

In a business landscape driven by data, the health of your database directly translates to the health of your organization. Customer records, sales pipelines, marketing campaign metrics, and critical operational data all depend on a well-managed system. Too often, however, organizations grapple with slow queries, security vulnerabilities, and unexpected downtime. These are not just technical glitches; they are symptoms of neglecting foundational principles.
This guide is designed to cut through the noise. We will provide a comprehensive roundup of eight crucial database management best practices that move beyond abstract theory. Instead of just telling you what to do, we show you how to do it with actionable steps to build a robust, secure, and high-performing data infrastructure.
For sales teams, this means faster access to lead information. For marketing agencies, it ensures reliable campaign data. For startups, it creates a scalable foundation for growth. Mastering these core practices will not only prevent costly disasters but also unlock new levels of efficiency and operational stability.
Let's dive into the specific techniques that separate thriving, resilient systems from fragile, inefficient ones. This article will cover the following essential topics:
- Database Normalization: Structuring your data for integrity and efficiency.
- Regular Backups and Recovery: Creating a bulletproof disaster recovery plan.
- Query Optimization: Making your database run faster and smoother.
- Security and Access Control: Protecting your most valuable asset.
- Monitoring and Maintenance: Proactively keeping your database healthy.
- Data Modeling and Schema Design: Building a solid foundation from the start.
- Scalability and High Availability: Ensuring your database grows with you.
- Documentation and Version Control: Creating a clear and manageable system.
1. Database Normalization
Database normalization is a fundamental technique in database management best practices, focusing on organizing the columns and tables of a relational database to minimize data redundancy and improve data integrity. In simple terms, it's about structuring your data in a way that avoids duplication and makes the database more efficient, flexible, and easier to maintain.
The process involves dividing larger tables into smaller, well-structured tables and defining relationships between them. This prevents issues like update anomalies, where changing data in one location requires changes in several others, leading to inconsistencies. For example, an e-commerce platform like Amazon doesn't store a customer's address with every single order. Instead, it stores customer information in one table and order information in another, linking them with a unique customer ID. This ensures that if a customer updates their address, it's changed in only one place.
The Core Principles: Normal Forms
Normalization follows a series of guidelines called normal forms (NF). While there are several levels, the first three are the most critical for practical database design.
- First Normal Form (1NF): Ensures that each column in a table holds a single, atomic value, and each record is unique.
- Second Normal Form (2NF): Builds on 1NF and requires that all non-key attributes are fully dependent on the primary key, eliminating partial dependencies.
- Third Normal Form (3NF): Extends 2NF by removing transitive dependencies, meaning no non-key attribute depends on another non-key attribute.
This concept map visualizes the progression from 1NF to 3NF, showing how each form builds upon the last to create a more organized and efficient database structure.
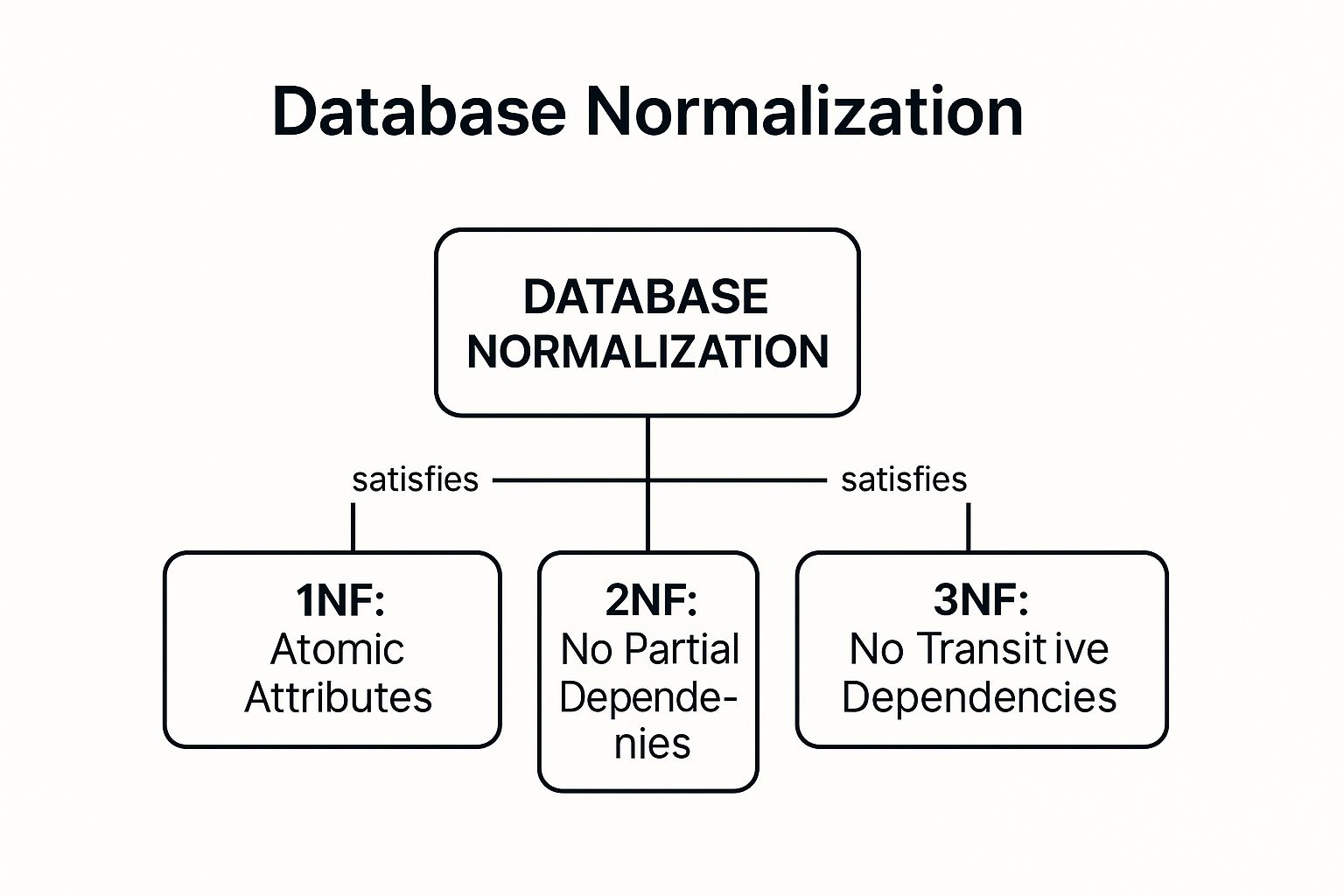
The visualization clearly illustrates that achieving 3NF requires satisfying the conditions of both 1NF and 2NF, highlighting the structured, step-by-step nature of the normalization process.
Actionable Tips for Implementation
For most applications, achieving Third Normal Form (3NF) offers an ideal balance between data integrity and performance. While higher forms exist, they can sometimes overcomplicate the design without significant benefits.
Key Insight: Don't treat normalization as an all-or-nothing rule. In some high-read, low-write scenarios, like data warehousing, intentionally denormalizing certain tables can improve query performance by reducing the need for complex joins.
To effectively implement normalization, start by using a database modeling tool like Lucidchart to visualize table relationships. This helps you identify potential dependencies and structural issues before writing any code. As you normalize, document all table relationships and constraints clearly. After implementation, always test query performance to ensure the new structure hasn't created any unexpected bottlenecks.
2. Regular Database Backup and Recovery Planning
A cornerstone of reliable database management best practices is establishing a comprehensive backup and recovery strategy. This practice is your ultimate safety net, ensuring business continuity by systematically creating copies of your data and having a clear, tested plan to restore it after a failure. It involves much more than just hitting "backup"; it's a holistic process of scheduling, testing, and secure storage designed to protect against data loss from hardware failures, cyber-attacks, human error, or natural disasters.
For example, global streaming services like Netflix can’t afford downtime. They utilize automated backups replicated across multiple AWS regions to ensure their massive content library and user data are always recoverable, no matter the disruption. Similarly, financial institutions like JPMorgan Chase implement real-time replication and frequent backups to safeguard transactional data, a non-negotiable requirement in their industry. This level of preparedness is what separates a minor hiccup from a catastrophic business failure.

This visual highlights two critical components of a robust strategy: a diversified storage approach (the 3-2-1 rule) and a continuous validation loop (the recovery test cycle), emphasizing that creating backups is only half the battle.
The Core Principles: Backup Types and Recovery Models
A successful strategy involves understanding different backup methods and choosing the right mix for your operational needs. The primary types are:
- Full Backups: A complete copy of the entire database. While the most straightforward for restoration, they are resource-intensive and time-consuming.
- Incremental Backups: Copies only the data that has changed since the last backup of any type (full or incremental). They are fast to create but can make restoration more complex.
- Differential Backups: Copies all data that has changed since the last full backup. These offer a balance, being faster to restore than incrementals but larger in size.
Actionable Tips for Implementation
The goal is not just to back up data but to guarantee its recoverability. A backup you can't restore is useless.
Key Insight: Your recovery plan is a living document, not a one-time setup. It must be tested and refined regularly to account for changes in your data volume, infrastructure, and business requirements. A successful test from six months ago doesn't guarantee a successful recovery today.
Start by implementing the 3-2-1 rule: maintain at least 3 copies of your data, store them on 2 different types of media, and keep 1 copy off-site. Schedule regular, automated recovery drills to simulate real-world failure scenarios and validate your procedures. Document every step of the recovery process clearly, and use backup compression and encryption to improve storage efficiency and security. Finally, set up automated monitoring to alert you to backup failures or integrity issues immediately.
3. Query Optimization and Performance Tuning
Query optimization is a critical practice in database management focused on improving the speed and efficiency of data retrieval operations. It involves analyzing and refining database queries to reduce response times, minimize server load, and enhance the overall user experience. At its core, this practice ensures that the database engine can find and deliver requested data in the fastest way possible.
Poorly written queries can consume excessive CPU, memory, and I/O resources, leading to slow application performance and system bottlenecks. For example, a high-traffic platform like Pinterest must optimize its MySQL queries to instantly load boards with billions of pins. By refining their indexing strategy and query structures, they ensure the system remains responsive despite handling a massive volume of data and user interactions. This proactive tuning is a cornerstone of effective database management best practices.
This visualization highlights the cyclical nature of performance tuning: identifying slow queries, analyzing their execution plans, implementing optimizations like indexing or rewriting, and then monitoring the impact.
The Core Principles: Query Execution and Analysis
Effective optimization starts with understanding how a database processes a query. The database engine's "query planner" or "optimizer" evaluates multiple ways to execute a query and chooses the one it estimates to be the most efficient. Your goal is to provide the planner with the best possible information and structure.
- Query Execution Plans: This is a roadmap showing the exact steps the database will take to run a query. Analyzing it reveals inefficiencies like full table scans where an index seek would be faster.
- Indexing: Proper indexing is paramount. Indexes act like a book's index, allowing the database to quickly locate data without scanning every row in a table.
- Statistics: Databases use statistics about data distribution to make smart decisions. Keeping these statistics up-to-date helps the query planner choose the best execution path.
Actionable Tips for Implementation
Start by using built-in database profiling tools, like SQL Server's Query Store or PostgreSQL's EXPLAIN ANALYZE, to identify the most resource-intensive queries. These are often the best candidates for optimization.
Key Insight: Avoid
SELECT *in production code. Explicitly listing the columns you need reduces data transfer, lowers memory usage, and can allow the database to use more efficient, index-only scans.
When you identify a slow query, examine its execution plan. Look for full table scans on large tables and create indexes on columns used in WHERE, JOIN, and ORDER BY clauses. For queries filtering on multiple columns, a composite index can provide a significant performance boost. Finally, consider implementing query result caching for frequently requested, static data to avoid hitting the database altogether.
4. Database Security and Access Control
Database security and access control are critical components of any robust database management strategy, focused on protecting sensitive data from unauthorized access, breaches, and malicious attacks. This practice involves a multi-layered approach that includes authentication to verify user identities, authorization to define what actions they can perform, and auditing to track all activities. It’s about building a secure fortress around your data.
A prime example is a healthcare system handling patient records. It must implement HIPAA-compliant encryption and strict access controls to ensure only authorized medical staff can view or modify patient data. Similarly, financial institutions protect banking databases with advanced security, including real-time fraud detection and classified data protection, ensuring that a bank teller cannot access the same system-level functions as a database administrator. These measures are essential for maintaining data confidentiality, integrity, and availability.
The Core Principles: Layered Defense
Effective database security is not about a single solution but a combination of defensive layers. These core principles work together to create a comprehensive security posture.
- Authentication and Authorization: Verifying who users are and what they are allowed to do. This is often managed through Role-Based Access Control (RBAC).
- Data Encryption: Protecting data both at rest (when stored on disk) and in transit (as it moves across the network).
- Auditing and Monitoring: Logging all database activities to detect suspicious behavior and ensure compliance with regulations like GDPR or HIPAA.
- Vulnerability Management: Regularly patching and updating database software to protect against known exploits.
This diagram illustrates how different security layers, from network controls to data encryption, work together to protect the core database.

The visualization shows that true security is achieved by implementing multiple, independent layers of defense, ensuring that a failure in one layer does not compromise the entire system.
Actionable Tips for Implementation
Start by implementing the principle of least privilege, which dictates that users should only be granted the minimum access rights necessary to perform their job functions. This simple rule drastically reduces the potential attack surface.
Key Insight: Security is not a one-time setup; it's an ongoing process. Regularly scheduled audits of user permissions and access logs are just as important as the initial configuration. Complacency is the biggest threat to database security.
To enhance your security posture, use Transparent Data Encryption (TDE) for sensitive databases, a feature offered by providers like Microsoft and Oracle. Always use parameterized queries or prepared statements in your application code to prevent SQL injection, one of the most common database attacks. Finally, enable automated database activity monitoring to receive real-time alerts for suspicious behavior, allowing you to respond to threats before they escalate.
5. Database Monitoring and Maintenance
Proactive database monitoring and maintenance is a critical database management best practice that involves continuous oversight of a database's health, performance, and resource utilization. Instead of waiting for a system failure, this approach focuses on preventing issues before they impact users. It combines real-time monitoring of key metrics with a schedule of regular upkeep tasks to ensure the database runs smoothly and efficiently.
This practice is essential for maintaining system reliability and performance. For example, a global service like Netflix relies on sophisticated monitoring to handle its massive streaming database infrastructure, ensuring near-constant uptime for its users. Similarly, Spotify monitors its databases in real-time to guarantee seamless music playback. These companies don't just fix problems; they actively look for early warning signs of trouble, like slow queries or rising CPU usage, and address them before they escalate.
The Core Principles: Proactive Health Checks
Effective monitoring and maintenance revolves around a few key activities that keep the database in optimal condition. These tasks are typically automated and scheduled to minimize disruption.
- Performance Monitoring: Continuously tracking metrics like CPU usage, memory consumption, disk I/O, and query execution times to identify bottlenecks.
- Index Maintenance: Regularly rebuilding or reorganizing indexes to combat fragmentation, which can significantly slow down data retrieval operations.
- Statistics Updates: Ensuring the database query optimizer has up-to-date statistics about data distribution, allowing it to choose the most efficient execution plans.
- Consistency Checks: Periodically running checks to detect and repair any data corruption or logical inconsistencies within the database.
This proactive cycle ensures that the database remains fast, reliable, and healthy, preventing the gradual performance degradation that can occur over time if left unchecked.
Actionable Tips for Implementation
The goal is to move from a reactive "break-fix" model to a proactive, preventive one. Tools from providers like SolarWinds and Datadog are designed specifically for this, offering comprehensive dashboards and alerting capabilities.
Key Insight: Establish a performance baseline. Without knowing what "normal" looks like for your database during peak and off-peak hours, it's impossible to accurately identify anomalies or measure the impact of changes.
To implement a robust monitoring strategy, start by setting up automated alerts for critical thresholds, such as disk space exceeding 85% or CPU usage staying above 90% for a sustained period. Schedule regular maintenance tasks, like index rebuilding, to run during off-peak hours to avoid impacting users. Use monitoring dashboards to visualize performance trends over time, which helps in identifying gradual degradation that might otherwise go unnoticed.
6. Data Modeling and Schema Design
Data modeling and schema design are foundational database management best practices that involve creating a conceptual blueprint of your data. This process translates complex business requirements into a logical and physical database structure, ensuring the system accurately stores, retrieves, and manages information. In simple terms, it's like creating an architectural plan before building a house; it defines the entities, their attributes, and the relationships between them.
A well-designed schema acts as the backbone of your application, directly influencing performance, scalability, and maintainability. For instance, Uber’s schema is meticulously designed to handle the real-time location data, trip statuses, and user information for millions of concurrent rides. Similarly, Salesforce's flexible schema allows businesses to customize data fields and objects, accommodating a vast range of industry-specific needs without compromising the core CRM structure. A thoughtful design minimizes future rework and prevents data inconsistencies.
The Core Principles: From Concept to Reality
Effective data modeling typically progresses through three distinct stages, each adding a layer of detail to the final design.
- Conceptual Model: A high-level view that identifies key business entities and their relationships without getting into technical details. It focuses on what the system contains.
- Logical Model: A more detailed representation that defines the attributes for each entity, specifies primary and foreign keys, and outlines relationships more formally. It focuses on how data is structured, independent of a specific database system.
- Physical Model: The final implementation-ready design that translates the logical model into a specific database management system (DBMS). It includes data types, indexes, and other physical storage details.
This structured approach ensures that the database schema is not only technically sound but also perfectly aligned with the strategic goals of the business.
Actionable Tips for Implementation
The initial design phase is the most critical; a mistake here can be costly to fix later. Start by creating a conceptual model with tools like ERwin Data Modeler or Lucidchart to map out business processes and stakeholder requirements.
Key Insight: Don't design your schema in isolation. Validate your logical model with business stakeholders before moving to the physical design. This ensures the database will meet their needs and prevents misunderstandings that could lead to significant rework down the line.
When implementing the physical model, use standardized naming conventions for all tables, columns, and constraints to improve clarity and maintainability. Choose the most appropriate data types for each column; using an unnecessarily large data type can waste storage and slow down queries. Finally, document your schema thoroughly, including business rules and constraints, to guide future development and maintenance efforts.
7. Database Scalability and High Availability
Database scalability and high availability are critical database management best practices that ensure your system can handle growth while remaining operational at all times. Scalability is the ability to increase capacity to manage a growing workload, while high availability ensures the database remains accessible with minimal downtime, even if components fail. These two concepts work together to create a resilient, high-performance database architecture.
This is essential for modern applications that cannot afford outages or slow performance as user traffic increases. For instance, a platform like WhatsApp must process billions of messages daily without interruption. It achieves this through horizontal scaling (sharding), where data is partitioned across many servers. This strategy, combined with replication and automated failover, ensures that if one server goes down, the system continues to function seamlessly, providing the 24/7 reliability users expect.
The Core Principles: Scaling and Availability Strategies
To build a robust system, it's vital to understand the primary methods for achieving scalability and high availability. These strategies form the foundation of a database that can grow and withstand failures.
- Vertical Scaling (Scaling Up): Involves adding more resources (CPU, RAM, storage) to a single server. It's simpler to implement but has a physical limit and a single point of failure.
- Horizontal Scaling (Scaling Out): Distributes the workload across multiple servers (nodes). This method, often implemented via sharding or partitioning, offers virtually limitless scalability and better fault tolerance.
- Replication and Failover: Creating and maintaining copies (replicas) of your database across different servers. If the primary database fails, an automated failover process seamlessly switches to a replica, ensuring continuous service.
These principles are not mutually exclusive. A comprehensive strategy often combines horizontal scaling with robust replication to create a system that is both highly scalable and highly available. For example, Amazon Web Services (AWS) popularized these concepts with its RDS Multi-AZ deployments, which automatically replicate data to a standby instance in a different "Availability Zone" for instant failover.
Actionable Tips for Implementation
For most growing applications, planning for horizontal scaling from the beginning is far more effective than trying to retrofit it later. Start by designing your application to be stateless, which makes distributing traffic across multiple database nodes much easier.
Key Insight: Don't just focus on the primary database. Use read replicas to offload read-heavy queries, freeing up the primary server to handle write operations. This simple step can dramatically improve performance and user experience without complex re-architecting.
To effectively implement these practices, use connection pooling to manage database connections efficiently and prevent resource exhaustion. When sharding, choose a sharding key that ensures even data distribution to avoid "hotspots" on specific servers. Finally, implement robust monitoring and alerting for replication lag to catch synchronization issues before they impact data consistency or system availability.
8. Documentation and Version Control
Documentation and version control are essential database management best practices for tracking, understanding, and reliably deploying database changes. This involves maintaining a detailed record of the database schema, procedures, and configurations, while using version control systems to manage all structural and data-related changes like a software development project.
This structured approach ensures that every modification is deliberate, transparent, and reversible. It prevents the chaos of untracked manual changes that can lead to inconsistencies between development, testing, and production environments. For example, Atlassian maintains comprehensive database documentation and version control for its collaboration tools, allowing their distributed teams to work coherently on a complex, evolving database schema without conflicts. This discipline is crucial for team collaboration and maintaining database integrity.
The Core Principles: Tracking and Communication
The foundation of this practice rests on treating your database schema as code. This means every change, from adding a column to updating a stored procedure, is scripted, committed to a repository, and reviewed.
- Database-as-Code: All changes to the database structure (DDL) and reference data (DML) are stored as scripts in a version control system like Git.
- Migration Tools: Specialized tools like Flyway or Liquibase manage the application of these scripts in a specific order, ensuring each database environment is at the correct version.
- Comprehensive Documentation: This goes beyond code comments. It includes schema diagrams, data dictionaries defining tables and columns, and explanations of business logic embedded in stored procedures.
This methodical process transforms database management from an ad-hoc task into a predictable and auditable engineering discipline.
Actionable Tips for Implementation
Start by integrating a database migration tool into your development pipeline. These tools automate the process of applying and tracking schema changes, which is a significant step up from manual script execution.
Key Insight: Implement a mandatory code review process for all database changes, just as you would for application code. This practice catches potential issues early, ensures adherence to standards, and spreads knowledge across the team.
To apply this effectively, begin by scripting your entire existing database schema as a baseline. Use tools like Flyway or Liquibase to manage all subsequent changes through versioned migration scripts. Maintain clear, descriptive naming conventions and comments within your database objects. Finally, ensure your documentation is a "living" document, updated in tandem with every schema change to prevent it from becoming obsolete.
Best Practices Comparison Matrix of 8 Key Database Strategies
| Item | Implementation Complexity | Resource Requirements | Expected Outcomes | Ideal Use Cases | Key Advantages |
|---|---|---|---|---|---|
| Database Normalization | Moderate to high; requires careful design and expertise | Moderate; mainly design and maintenance effort | Reduced data redundancy, improved data integrity | Relational databases needing consistency and efficiency | Eliminates redundancy, improves integrity |
| Regular Database Backup and Recovery Planning | Moderate; involves scheduling and management | High; requires significant storage and backup infrastructure | Data protection, minimal downtime, disaster recovery | Critical systems needing fault tolerance | Ensures business continuity and data protection |
| Query Optimization and Performance Tuning | High; requires specialized knowledge and continuous tuning | Moderate; tools and monitoring resources | Improved query performance and reduced resource use | High-transaction or large-scale database systems | Enhances speed and resource efficiency |
| Database Security and Access Control | Moderate to high; involves policies and technical controls | Moderate to high; encryption and monitoring tools | Protected data, regulatory compliance, audit trails | Systems handling sensitive or regulated data | Strong data protection and compliance adherence |
| Database Monitoring and Maintenance | Moderate; requires tools and skilled personnel | Moderate; monitoring infrastructure and alerting | Proactive issue detection, consistent performance | Systems requiring high availability and stability | Prevents downtime, optimizes resource usage |
| Data Modeling and Schema Design | High; demands upfront analysis and iterative refinement | Low to moderate; mainly design phase effort | Well-structured, scalable database schemas | New database projects and redesigns | Clear data blueprint, supports scalability |
| Database Scalability and High Availability | High; complex architecture and ongoing management | High; infrastructure and specialized expertise | Scalable, fault-tolerant, always-available databases | Large-scale, high-traffic applications | Supports growth and continuous operation |
| Documentation and Version Control | Moderate; requires discipline and tool adoption | Low to moderate; tools and process overhead | Traceable changes, reliable deployments | Development teams with multiple environments | Improves collaboration and change management |
From Theory to Practice: Mastering Your Data Ecosystem
Navigating the complexities of database management can feel like a monumental task, but the journey from theoretical knowledge to practical mastery is built one best practice at a time. Throughout this guide, we have explored the essential pillars that support a robust, secure, and high-performing data infrastructure. From the foundational logic of Normalization and Schema Design to the proactive strategies of Monitoring, Backup Planning, and Query Optimization, each principle serves a critical role.
These aren't just abstract concepts; they are the strategic blueprints for building a data ecosystem that drives business growth rather than hindering it. Implementing these database management best practices is the difference between a system that merely stores data and one that actively works as a competitive advantage. It's the core of what allows your sales teams to access reliable customer information, your marketing campaigns to leverage clean and accurate data, and your entire organization to make decisions with confidence.
Synthesizing the Core Principles
The true power of these practices is unlocked when they are viewed not as a checklist to be completed, but as an integrated, continuous cycle of improvement.
- Design & Structure: It all begins here. Solid Data Modeling and Normalization prevent data anomalies and create an efficient, logical foundation for everything that follows.
- Performance & Availability: Proactive Query Optimization and planning for Scalability ensure that your database meets user demands swiftly and remains accessible, even as your business grows.
- Security & Resilience: A database is useless if it's compromised or lost. Rigorous Security and Access Control combined with disciplined Backup and Recovery plans form an essential shield against threats and disasters.
- Maintenance & Governance: Finally, consistent Monitoring, diligent Documentation, and Version Control transform your database management from a reactive, fire-fighting exercise into a proactive, strategic operation.
Think of it this way: a powerful engine is only as good as its maintenance schedule. Similarly, a well-designed database only retains its value through consistent care and attention to these interconnected practices.
Your Actionable Path Forward
Moving from reading to doing is the most critical step. Don't feel overwhelmed by the need to implement everything at once. Instead, adopt a phased approach to integrate these database management best practices into your workflow.
- Conduct a Health Check: Start with an audit. Where are your biggest pain points? Are queries slow? Is data security a concern? Use the principles of Database Monitoring to identify your most urgent needs.
- Secure Your Foundation: If you do nothing else, prioritize Backups and Security. Schedule automated backups and test your recovery process this week. Review user permissions and enforce the principle of least privilege immediately. These actions provide the most significant immediate return on protecting your assets.
- Optimize for Impact: Use performance analysis tools to identify the top 3-5 slowest queries affecting your applications. Focus your Query Optimization efforts here for quick, noticeable improvements in user experience.
- Document as You Go: Institute a new rule: no schema change is complete until it's documented. Start building your data dictionary today, even if it's just a simple document. This habit will pay enormous dividends in the future.
The journey toward mastering your data ecosystem is ongoing. The goal is not a one-time fix but the cultivation of a culture where data integrity is paramount. By consistently applying these database management best practices, you transform your data from a simple collection of records into your organization’s most reliable and strategic asset. This commitment ensures that every email campaign, sales call, and business decision is built on a foundation of clean, accessible, and trustworthy data, paving the way for sustainable success.